HW/SW Co-Simulation
Anne Powell and Shawn Lin
Introduction to VLSI and ASIC Design
Winter 2000
In late 1997 and early
1998, there was a flurry of press coverage on hardware/software co-simulation.
Several vendors attempted to shape the topic to position their products
as the best solution, resulting in a mishmash of imprecise terms.
What is HW/SW co-simulation? The most basic definition is: manipulating
simulated hardware with software. Given an ASIC-based product that will
contain some significant amount of software, the goal of co-simulation
is to verify as much of the product functionality, hardware and software,
as possible before fabricating the ASIC. For a small system, you
might be able to run a significant portion of the product software, in
a large system, you may only be able to run a tiny fraction. This paper
will examine the methods and motivations of HW/SW co-simulation. Co-design
will be discussed as part of the overall simulation strategy.
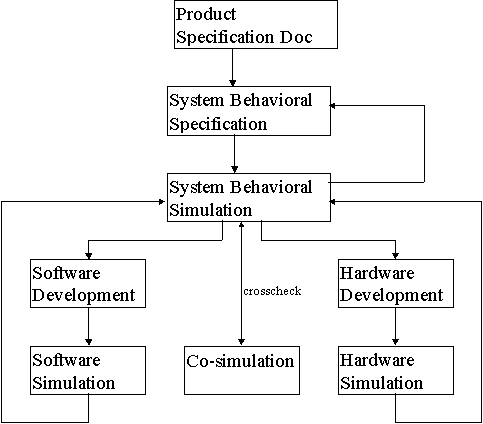
Simulation Strategy Overview
Co-simulation is only one
part of a product simulation strategy. In the past, co-simulation has been
done late in the process, after the hardware has been deemed to be mostly
working, which is to say, stable enough that running software against it
was worthwhile. Software developers were often left to develop code for
months with severely limited ability to test what they had written before
they forgot what they were trying to do. Painful integration efforts came
late in the design cycle, and minor miscommunication became major design
flaws. Most of these problems would be patched over in software at the
price of performance. Some would be fatal and require a costly re-spin
of the silicon.
Behavioral model simulation
has matured, and simulation tools in general have improved to allow better
simulation throughout the development cycle, starting from the earliest
ideas of what the product should do. Co-design tools provide project architects
with a simulation environment at a very high level of abstraction. Think
of it as system simulation at 30,000 feet. These tools help convert the
English description of functionality into a formal specification language,
and allow designers to work out the functional split between the hardware
and the software in a simulation environment.
Basic debug of the implementation
can proceed with the well known event and cycle driven simulators. Integration
of hardware and software components can be done in a co-simulation environment
long before fabrication. If co-design tools were used, the high level model
can be compared against the actual implementation. These tools and techniques
can be used to greatly reduce the time between a bug's creation and its
discovery, which the testing community generally recognizes as the cheapest
way to fix them.
Components of Simulation
The first most obvious component of any co-simulation effort is
a hardware design that will eventually be driven by software in a significant
way. At one extreme, a memory chip, although it may be used by software,
 isn't driven differently by software than by a hardware testbench. At the
other extreme, a CPU is not very interesting unless there is software driving
it. In the middle, there are hundreds of ASICs which may contain one or
more CPUs, or are coupled to an external CPU which exerts control over
the ASIC.
isn't driven differently by software than by a hardware testbench. At the
other extreme, a CPU is not very interesting unless there is software driving
it. In the middle, there are hundreds of ASICs which may contain one or
more CPUs, or are coupled to an external CPU which exerts control over
the ASIC.
Given that there is software
in the end product, the next piece of the co-simulation environment is
the simulation platform, the engine which will do the simulation. The engine
may be the same PC or workstation that the designers use for the rest of
their work. Workstation based simulations are often considered pure simulations,
because everything is faked. Everything exists as a process on the computer.
Hybrid platforms use
a special co-processor to run parts of the simulation. Hardware assisted
simulation offloads part of the simulation to special hardware while peripheral
circuits and testbenches remain in the software simulator. Zycad is a major
vendor with their Lightspeed product. They boast speeds of 4K instructions
per second on designs like the Intel 80486, which is about 300,000 gates
and runs at 75-100 MHz. This translates to about 1 second of simulated
time per week.
Alternatively, there are
special hardware engines, also called emulators, which run the whole design.
Quickturn, a division of Cadence, is one of the major suppliers of emulation
engines. Both authors of this paper have hands-on experience with Quickturn
products.
 Quickturn has two products lines. The Mercury products are based
on a large array of FPGAs. The emulated design can be run at speeds up
to 10% of real time. The FPGA based systems are good for medium to large
designs and cost a few hundred thousand dollars. The Cobalt products are
massively parallel CPU systems designed by IBM, probably from IBM's own
in-house simulation efforts, which are known to be highly advanced. Cobalt
boasts similar speeds, but scales better for very large designs, and multichip
simulations. A Cobalt system costs several million dollars, but can run
multichip designs totaling 5 millions gates or more at speeds of one second
emulated time per hour.
Quickturn has two products lines. The Mercury products are based
on a large array of FPGAs. The emulated design can be run at speeds up
to 10% of real time. The FPGA based systems are good for medium to large
designs and cost a few hundred thousand dollars. The Cobalt products are
massively parallel CPU systems designed by IBM, probably from IBM's own
in-house simulation efforts, which are known to be highly advanced. Cobalt
boasts similar speeds, but scales better for very large designs, and multichip
simulations. A Cobalt system costs several million dollars, but can run
multichip designs totaling 5 millions gates or more at speeds of one second
emulated time per hour.
Special emulation hardware
is expensive, but the emulated system will run a thousand times faster
than simulations done on a PC. To run one second of simulated time
on an emulator might take an hour. The same simulation a thousand times
slower takes forty two days, assuming your PC stays up that long. Emulators
allow designers of large products to find a class of problem that cannot
be found in simulation. In addition to being fast, emulators can attach
to real devices. For instance an emulated video chip could be attached
to a real monitor. An emulated router using Quickturn's Ethernet SpeedBridge
could route real network traffic, albeit slowly. This is not supported
by PC-based simulators.
Regardless of the engine
used, there is a software algorithm used to perform the simulation. The
more precise algorithm is event driven simulation, also called gate level
simulation. Every active signal is calculated for every device as it propagates
through during a clock cycle. Each signal change is simulated not only
for its value, but also for the exact time at which it occurs. The output
of a 3-input NAND might be calculated three times during a clock cycle
as each input signal arrives. The resulting simulation will show multiple
signal strengths: strong and weak, high and low, as well as indeterminate
and undefined values. Event driven simulation is an excellent algorithm
for finding timing problems like race conditions, but is computationally
intensive, and thus slower.
To speed up the simulation
process, cycle-based simulators gloss over some of the details. Instead
of calculating each signal as it propagates through each level of logic,
cycle based simulators calculate the state only at clock edges, and generally
only calculate '0' and '1' values. This is valuable for running the large
number of tests needed to verify functionality of a complex design. On
the same PC, a cycle based simulator may run 3 to 10 times faster and use
20% of the memory of an event driven simulator. This is a significant difference
if only PC based simulators are available, but simulation speeds tend to
be much more strongly related to the speed of the engine they run on. The
difference between cycle based and event driven simulators is at best a
factor of ten. The speed difference between either of those and an emulator
is a factor of a thousand.
A third simulation algorithm
is data-flow simulation, which further simplifies the model. Signals are
simply represented as a stream of values without an explicit notion of
time. Functional blocks are linked by signals. Blocks are executed when
some number of signals are pending at the inputs. The simulated block then
consumes values from its inputs and produces new values on its outputs.
The simulators scheduler determines the order of block execution. This
is a very high level of abstraction which is useful for proving algorithmic
correctness, and is typically employed in the early stages of co-design.
Simulation will place some
requirements on the hardware design. Most simulators can handle behavioral
models, while emulators require a synthesizable design. Some simulators
may not handle all VHDL or all Verilog constructs. Cycle based simulators
can handle asynchronous designs, but at a major performance penalty. It
is best to pick which simulator or simulators you plan to use early in
the design cycle. Because of the relative strengths and weaknesses of different
simulation tactics, projects may use several different kinds of simulators
in parallel. In fact, even on a single problem you might want to run the
design on an emulator (fast, but difficult to look at signals) until it
is within a few hundred microseconds of the failure point, export the state
of the system into a simulator (slow, with superior signal tracing) and
continue until the failure is reached. Quickturn supports this method between
the Quickturn boxes and their cycle-based simulator.
Simulation environments
can place significant restrictions on the application software. Programmers
will almost certainly need an alternate build version for simulation which
removes any user interface code, removes references to chips which are
not present in the simulation environment, reduces table sizes and other
changes for functionality and speed. Speed is a major concern in simulation
environments. For a 100MHz processor being simulated at 1ms an hour, initializing
a 4Kb table could take minutes. Apparently trivial tasks can quickly add
up to huge simulation times.
Methods of Co-simulation
One relatively new
area of co-simulation is co-design. Based on the theory of simulating early
and often, co-design is a way to simulate at a very high level of abstraction,
prior to the actual implementation. These simulations follow the theme
of trading details for run-time speed. By creating a functional model which
can be tested, system designers can make sure the requirements are clear.
The difference between English language descriptions and the functional
model can be resolved early, rather than after the low-level implementation
is complete. Furthermore, by making a single model of both hardware and
software functionality, the design boundary between the two is effectively
removed. Historically, the hardware/software boundary has been a source
of trouble.
Having a running model
also allows engineers to test different hardware/software functionality
splits for performance and get some rough timing estimates for various
ideas. In the past, the decision of what should be implemented in hardware
versus software was based primarily on the past experiences of the design
team, rather than any hard data. Running a functional model also allows
engineers to find fundamental bugs in the design before implementing them.
These models can be used later in the product lifecycle to quickly assess
the impact of requirements changes.
The POLIS project at UC
Berkeley is one group researching co-design. The focus of this effort appears
to be first making an informed decision about what functions to implement
in hardware versus software, and second to prove correctness of the algorithms.
POLIS is based on finite state machines, and thus leverages much of the
formal verification work which has been done in that area. According to
POLIS, Cadence's Cierto VCC is based on ideas from POLIS. Cadence's white
papers describe an broad based industry initiative to define Cierto.
Synopsys COSSAP and Eaglei
tools promise a way to check the implementation against the original algorithmic
specification for function equivalence although the 1998 white paper which
makes this promise also indicates that at the time, this was not "straightforward".
COSSAP however did claim the ability to generate both C and HDL code from
the functional model, which is a useful time saver.
Interestingly, many of
the methodology suggestions made by co-design tool vendors sound very familiar
to software engineers. The waterfall method of top down, sequential design
where the requirements begat the specification begat implementation begat
product, is being traded for iterative refinement. The high level functional
language implementation step of the process sounds like a different implementation
of Booch's Universal Modeling Language, which is popular among Ada and
some C++ programmers. Even the ability of the co-design tools to generate
skeleton code to get the implementation started, is similar to software
life-cycle tools currently available.
The standard method of
co-simulation is to run software directly on simulated hardware. This implies
that the CPU is part of the ASIC, or that a simulatable model of the CPU
is available. Amdahl was debugging their mainframe CPUs this way in the
early 1980's. In this method, the CPU is simulated at the same level as
the rest of the hardware. This is a good thing if you are designing the
CPU, but it may be a waste of valuable simulation resources if you bought
a CPU core from a trusted vendor. Another disadvantage of this method is
that software engineers will be using hardware debug tools to debug software,
which is not a lot of fun. A signal trace can tell a hardware engineer
a lot, but programmers work in a different way. Programmers usually only
care about the current state of the system, and the ability to stop at
certain points in the code. Hardware debug tools are not geared towards
this work style. Most hardware simulators and emulators do support a scripting
language like Tcl or Perl, and a graphical interface like Tk, so it is
possible for software engineers to write their own development environment.
Budget about one engineer-month to get something primitive but usable.
Another recent advance
in co-simulation is heterogeneous co-simulation. The idea here is to network
different types of simulators together to attain better speed.
 It also
affords better ability to match the task with the tool, simulating at a
level of detail which is most appropriate for each item under test. There
was a lot of press on this topic about two years ago, and many of those
articles identify this process only as "co-simulation", as if to indicate
this is the only way to do it. Synopsys Eaglei lets hardware run in any
of a number of simulation environments, and software run either native
on a PC/workstation or under an instruction-set simulator. The Eaglei product
provides an interface between the two. The first obvious advantage is that
designers can use tools which are familiar to them on each side. Programmers
can use all their favorite debugger tools to see software state and control
execution. If the CPU is loosely coupled to the design, heterogeneous co-simulation
is a useful shortcut. On the other hand, if the CPU could, for instance,
cause memory contention with other hardware blocks, using heterogeneous
co-simulation in this way could create major test coverage holes.
It also
affords better ability to match the task with the tool, simulating at a
level of detail which is most appropriate for each item under test. There
was a lot of press on this topic about two years ago, and many of those
articles identify this process only as "co-simulation", as if to indicate
this is the only way to do it. Synopsys Eaglei lets hardware run in any
of a number of simulation environments, and software run either native
on a PC/workstation or under an instruction-set simulator. The Eaglei product
provides an interface between the two. The first obvious advantage is that
designers can use tools which are familiar to them on each side. Programmers
can use all their favorite debugger tools to see software state and control
execution. If the CPU is loosely coupled to the design, heterogeneous co-simulation
is a useful shortcut. On the other hand, if the CPU could, for instance,
cause memory contention with other hardware blocks, using heterogeneous
co-simulation in this way could create major test coverage holes.
Many performance claims
have been made about the heterogeneous co-simulation environment. The situation
is complex enough that no single number can adequately describe all situations.
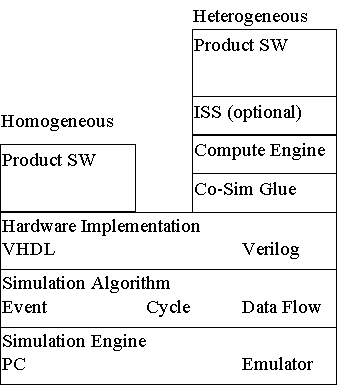 Since the software is not running at hardware simulation speeds, proponents
argue that things will run much faster. That's possible, but not guaranteed.
The first question to ask is, how fast is the software running when it
is not doing anything hardware related? You may be able to run the code
directly on a PC or workstation. Even if your target CPU architecture does
not match that of your PC/workstation, you may be able to use a cross-compiler
(a compiler, like the GNU C compiler, which can create executable code
for a large number of target architectures), as long as there is little
or no assembly language source code. Thus the product software written
in a high level language, targeted for a MIPS CPU, is cross compiled to
the SPARC instruction set, runs on a Sun workstation and communicates with
the simulated hardware via special function calls. If the software can
be run directly as a process on the workstation, then it will run at the
workstation's speed, about as fast as it gets. If the software cannot be
run directly, then it must be run under an instruction-set simulator, ISS.
An ISS simply interprets assembly language at the instruction level, which
is fine as long as you don't care about the CPU details. As a guess, an
ISS could probably run at 20% the speed of a native process, still blindingly
fast compared to running under a hardware simulator, or even an emulator.
Since the software is not running at hardware simulation speeds, proponents
argue that things will run much faster. That's possible, but not guaranteed.
The first question to ask is, how fast is the software running when it
is not doing anything hardware related? You may be able to run the code
directly on a PC or workstation. Even if your target CPU architecture does
not match that of your PC/workstation, you may be able to use a cross-compiler
(a compiler, like the GNU C compiler, which can create executable code
for a large number of target architectures), as long as there is little
or no assembly language source code. Thus the product software written
in a high level language, targeted for a MIPS CPU, is cross compiled to
the SPARC instruction set, runs on a Sun workstation and communicates with
the simulated hardware via special function calls. If the software can
be run directly as a process on the workstation, then it will run at the
workstation's speed, about as fast as it gets. If the software cannot be
run directly, then it must be run under an instruction-set simulator, ISS.
An ISS simply interprets assembly language at the instruction level, which
is fine as long as you don't care about the CPU details. As a guess, an
ISS could probably run at 20% the speed of a native process, still blindingly
fast compared to running under a hardware simulator, or even an emulator.
The second question, and
by far the more important, is how much time is the software accessing the
hardware. This ratio is known as the hardware density of the code.
Hardware density is not only application dependent, but will vary greatly
within a single application. In a loosely coupled CPU, a block of code
which is doing hardware initialization could access hardware every third
instruction. Other code blocks could be 5% or less. In a tightly coupled
design, every memory reference could go through simulated hardware. The
hardware density is the major factor in the overall speed of this style
of heterogeneous simulation. As any urban driver knows, it's not how fast
you go on the highway that determines your average speed, it's how many
stop lights you have to sit through. Each hardware access is the equivalent
of a stop light. Not only is the base hardware simulation speed slow, but
the tool that links the heterogeneous system together will introduce some
overhead. Further more, if the two simulation systems are not physically
on the same computer, then the corporate network speed, bandwidth, and
reliability also come into play.
This is not to say that
heterogeneous co-simulation is a bad idea. It can work well, but it is
not a panacea. It can be used when multiple chips need to be simulated
on different simulators. Perhaps an HDL model for the design under test
needs to interface with a UART, and the only UART model available runs
under a different simulator. Another interesting possibility for large
systems is to break the ASIC simulation across multiple workstations, which
could work well if different functional blocks in the ASIC are not too
tightly coupled.
Developing a Co-Simulation Strategy
Why go to all the trouble
and expense of co-simulation? In the words of one veteran test engineer,
"What you simulate is what you get." If it wasn't tested in simulation,
chances are good that it won't work in silicon. On the other hand,
the pace of the technology market demands that companies set product quality
goals that are not 100% bug free. Even if it were technically possible
to test everything, there would be severe schedule pressure to reduce the
test time. Therefore, the strategic issues of simulation must be
considered.
Hardware designers are
now running into the same problem that software designers have seen for
years. Fifteen years ago, no one would have considered putting the kind
of functionality into hardware that we are seeing today -- it was too hard
without a high level language. All the excess functionality was pushed
into software. Now, to a large degree because of HDLs but also because
of shrinking features size and growing die size, much more functionality
is being pushed into gates. The problem is that functional testing grows
exponentially with functionality. The software industry has been fighting
this problem for years, and has had limited success solving it. Formal
design methodologies, code reviews, and code re-used have helped, but in
the end, large products require large test efforts. For ASICs, it is far
preferable to do the large test effort prior to fabrication, but improved
simulation algorithms can barely keep up with the increased design complexity.
Emulation engines help, but have serious cost and usability issues. The
issue is further aggravated by the shrinking product cycle. A year of simulation
is seldom an option, but fabricating an ASIC too early leads to extended
system bringup and possible respins.
Therefore, the first step
in developing a simulation strategy is determining how thoroughly to test
each piece of the system and in what environment. Unless health and safety
are involved, you wont be able to do everything that should be done, but
you will probably be able to do everything that the team agrees must be
done. As useful technique is to develop a Must-Should-Could test list.
The categories are broad enough that the engineering staff can generally
agree, and management seldom attempts to cut items from the Must list.
A powerful testing technique
is to use a multi-pronged functional test strategy to build levels of assurance.
Basic tests prove initial functionality, more complex tests build upon
what is known to be working. This is a powerful technique because any single
test method leaves coverage holes. For instance, even though an event-driven
simulator is the closest model of the real hardware, its slowness is a
coverage hole few tests can be completed in the allocated time. For any
test decision, it is critical to understand not only what you have decided
to cover, but what you have decided to neglect. Managing the tradeoffs
is as important for a successful test effort as it is for any other part
of the engineering process.
A simulation strategy might
call for the functional specification to be written as a functional model
(co-design). That model would be used to develop some high level functional
tests. The hardware and software designers would start building their functional
blocks. Hardware designers could do block testing with an event-driven
simulator. Software designers could do basic debug using either an ISS
or a cross-compiler with the hardware calls either stubbed out (do nothing),
or faked (pretend to do something). If the functional model was detailed
enough, the software could even interface to that. As blocks are completed,
they could be dropped into the functional model and regression tested using
the high level functional tests.
Of course, as real components
replace functional models, simulation speed will degrade proportionally
to the amount of work the simulator is being asked to do. Real simulation
speed is highly dependent on the simulation engine, the simulation algorithm,
the number of gates in the design, and whether the design is primarily
synchronous or asynchronous. The speed and relatively low cost of cycle
based simulators may make them seem like a good compromise position, but
they are not sufficient on their own to test physical characteristics of
the design, they must be used in conjunction with either event driven simulators,
or with static timing analysis.
Perceived simulation speed,
i.e. how much work engineers are actually getting done, is dependent on
the time it takes from making a hardware change to the time you can start
running cycles again, how many cycles need to be run to find the next problem,
how easy it is to determine the cause of problems, and how much time the
system software spends doing uninteresting housekeeping chores. Cycle based
simulators and emulators may have long compilation (also called elaboration)
times which require designers to wait from thirty minutes to several hours
after a source change before they have a runnable model. In addition, emulators
may have significant load times before the model can actually run any cycles.
Therefore, these methods are not really desirable early in the design cycle
when many hardware changes are being made. Event driven and cycle based
simulators have fairly equal debugging environments, all signals are available
at all times. Emulators on the other hand, require the list of signals
to be traced to be declared at compilation time. If the next problem can
be found in a few microseconds of simulated time, then slower simulators
with faster compilation times are appropriate. If the current batch of
problems all take a couple hundred milliseconds, or even seconds of simulated
time, then the startup overhead of cycle based simulation or even an emulator
is worth the gain in run time speed.
Another interesting issue
arises for projects which use multiple simulation environments, is the
portability of testbenches. Using testbenches to power automated regression
test suites is an excellent technique, but moving testbenches between simulation
platforms can be an issue. HDL benches can move between simulators, but
may be harder to move to emulators, due to the requirement for synthesizable
code. Benches written in C may run significantly faster than HDL benches
on a cycle based simulator, but not at all on an event driven simulator.
Problems which require
a long time to happen are also likely to be found one the chips are back
from the foundry. A very fast simulation environment can help reduce the
amount of time spent in the lab trying to get a test case which fails immediately
to human perception. It is almost impossible to track hardware issues down
to a line of source code in the lab. Being able to recreate problems in
simulation is very important if the silicon is broken. Even if the problem
is not fixed in hardware, it is very risky to patch a partially understood
problem in software. If the problem is not fully understood software may
only succeed in hiding the problem long enough for it to resurface in a
higher stress environment.
One of the most important
parts of co-simulation strategy is determining which parts of the system
software to run and how much software debug can be done without the hardware.
Its very easy for software engineers to forget that only a few milliseconds
is a significant amount of time in simulation. The software engineer involved
in simulation will need to go through the code and disable functionality
which is too costly for simulation, or if the sequence is important, find
ways to reduce its execution time. A classic example is bypassing the software
loading sequence in simulation, and start most simulations with the memory
image of software already in place. If the boot sequence is complex, then
one simulation test would be to run part of the boot sequence, but once
the first block of data has been moved, there is not much reason to continue
the loop, especially if it will take weeks of simulator time. Another classic
software simulation problem is the issue of timer controlled actions. Code
which is triggered once a second may not be run at all in simulation, unless
specific action is taken to expedite the timer event.
Part of the software co-simulation
decision must be based on who will be programming the end product. If the
only code will be written in-house by embedded systems programmers, then
there is much more tolerance of arcane protocols and the occasional bug
work-around. On the other hand, if the device will be programmed by the
end-users, it is much more important that it work smoothly with software
as programmers would think to use it, or at least in a way which can be
effectively documented. The latter case places a much heavier burden on
co-simulation. Customer visibility should always act as a red flag on any
problem encountered.
The choice of whether
or not to pursue a heterogeneous co-simulation environment could be forced
by lack of availability of some models. If the plan calls for board level
simulation, you may not be able to get netlists for some vendor supplied
parts. They may only be willing to provide functional models. The commonly
implied environment of HW/SW heterogeneous co-simulation is where the CPU
is available (or is needed) only at the functional level. If the CPU is
very tightly coupled to the rest of the hardware, simulating it at a much
higher level of abstraction than the rest of the system could lead to trouble
later, but for many systems this is not an issue.
The degree of fidelity
between the simulated environment and the real world is both a requirement
of simulation and a constantly shifting target throughout the simulation
effort. Accuracy that is unavailable at the very early stages is crucial
at various points in the process. But there are many times where it is
preferable to trade high fidelity for speed.
Summary
We have discussed some of the issues and tradeoffs
involved in co-simulating hardware and software. Thanks in large part to
HDLs, the worlds of the logic designer and the programmer are converging
somewhat. On some ASICs, the hardware and software will be very tightly
coupled, in which case the co-simulation effort is crucial. Even in designs
where software exists primarily for initialization co-simulation should
be an important part of the design process, if for no other reason
than to give the software team a place to try their code. Although the
questions are largely the same for all projects, the answers for how to
achieve successful co-simulation are different for every project, for every
mix of hardware and software, and for every set of quality goals.
last update: 3/6/00